搜索提示
1. 问题背景
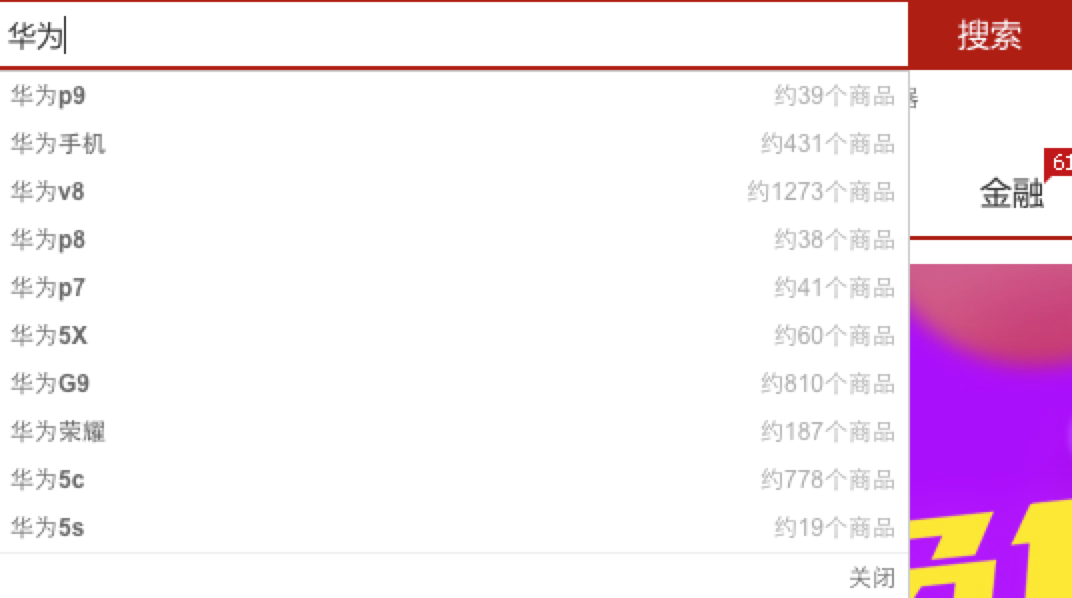
搜索关键字智能提示是一个搜索应用的标配,主要作用是避免用户输入错误的搜索词,并将用户引导到相应的关键词上,以提升用户搜索体验。下面是京东的搜索提示功能:
2. 需求分析
能够根据现有的商品自动生成可用的提示词
公司客户现状决定了不可能有人人工维护提示词,需要由系统自动生成可用的提示词支持前缀匹配原则
在搜索框中输入“海底”,搜索框下面会以海底为前缀,展示“海底捞”、“海底捞火锅”、“海底世界”等等搜索词;输入“万达”,会提示“万达影城”、“万达广场”、“万达百货”等搜索词。同时支持汉字、拼音输入
由于中文的特点,如果搜索自动提示可以支持拼音的话会给用户带来更大的方便,免得切换输入法。比如,输入“haidi”提示的关键字和输入“海底”提示的一样,输入“wanda”与输入“万达”提示的关键字一样。支持多音字输入提示
比如输入“chongqing”或者“zhongqing”都能提示出“重庆火锅”、“重庆烤鱼”、“重庆小天鹅”。支持拼音缩写输入
对于较长关键字,为了提高输入效率,有必要提供拼音缩写输入。比如输入“hd”应该能提示出“haidi”相似的关键字,输入“wd”也一样能提示出“万达”关键字。支持英文、拼音大小写输入
提示不区分大小写,输入“WD“和“wd”一样的效果,输入“HAIDI”、“Haidi”、“HAiDi” 和“haidi”相同的效果。支持单词或者汉字之间的空格
由于输入法的关系,有时单词或者汉字之间会多输入空格,应该对这种情况进行容错。输入“w d”和“wd”应该是一样的效果;输入“wan da”和“wanda”也是一样的效果。考虑关键字的商品数量因素进行排序
一般来讲,关键字的商品数量越多,表示用户购买该关键字下的商品的几率越大,因此提示词排序应该考虑商品数量。基于用户的历史搜索行为,考虑关键字热度因素进行排序
为了提供suggest关键字的准确度,最终查询结果,根据用户查询关键字的频率进行排序,如输入[重庆,chongqing,cq,zhongqing,zq] —> [“重庆火锅”(f1),“重庆烤鱼”(f2),“重庆小天鹅”(f3),…],查询频率f1 > f2 > f3。支持运营手工插入提示词、调整提示词顺序**
系统应该支持由运营人员手工插入提示词,并调整提示词顺序,这样可以引导客户搜索希望的关键词。
3. 解决方案
3.1. 生成拼音
汉字转拼音
用户输入的关键字可能是汉字、数字,英文,拼音,特殊字符等等,由于需要实现拼音提示,我们需要把汉字转换成拼音,我们考虑使用pypinyin库实现转换。拼音缩写提取
虑到需要支持拼音缩写,汉字转换拼音的过程中,顺便提取出拼音缩写,如“chongqing”,"zhongqing"--->"cq",”zq”。多音字全排列
要支持多音字提示,对查询串转换成拼音后,需要实现一个全排列组合。支持单词和汉字空格
对单词或者汉字拼音组合时,增加一种中间带空格的组合不区分大小写
增加全大写和小写的组合。
完整的代码如下,可以看到python代码还是很简洁的,只有22行代码
def get_pingyin_combination(self, input_str, separator=SEPARATOR):
"""
获取词汇的拼音综合,多音字会有多个读音组合
水果 的返回结果为:["shui guo","shuiguo","s g","shg","sh g","sg"]
"""
if not input_str:
return []
pinyin_list = self.combine_element(pinyin(input_str, style=pypinyin.NORMAL, heteronym=True), 0)
first_letter_list = pinyin(input_str, style=pypinyin.FIRST_LETTER, heteronym=True)
initials_letter_list = pinyin(input_str, style=pypinyin.INITIALS, heteronym=True)
merge_letter_list = map(lambda a_list, b_list: filter(lambda item: item, set(a_list + b_list)),
first_letter_list, initials_letter_list)
pinyin_list += self.combine_element(merge_letter_list, 0) + self.combine_low_up_chars(input_str)
pinyin_list += map((lambda element: element.replace(separator, '')), pinyin_list)
return list(set(pinyin_list))
def get_integrated_pingyin_strs(self, input_str):
"""
获取词汇的完整拼音,包含多音词
"""
if not input_str:
return []
return self.combine_element(pinyin(input_str, style=pypinyin.NORMAL, heteronym=True), 0, '')
def combine_element(self, input_list, start, separator=SEPARATOR):
"""
组合各个字的拼音
"""
if start == len(input_list) - 1:
return input_list[start]
return [separator.join(element) for element in
product(input_list[start], self.combine_element(input_list, start + 1, separator))]
def combine_low_up_chars(self, word):
"""
组合大小写字符
"""
if re.search(self.english_filter_regr, word):
return [word.lower(), word.upper()]
return []
3.2. 用户搜索关键词收集
用户在使用搜索引擎查找商品时,会输入大量的关键字,每一次输入就是对关键字的一次投票,那么关键字被输入的次数越多,它对应的查询就比较热门,所以需要把查询的关键字记录下来,并且统计出每个关键字的频率,方便提示结果按照频率排序。用户搜索时,搜索引擎异步把用户每次搜索使用的搜索关键词记录下来,每个关键词的长度为1-40字节。
3.3. 提示词自动生成
搜索关键词提示是为了帮助用户更好的搜索到商品,那么反向推导,我们可以从商品数据中自动提取出提示词。
我们从商品的关键字段(在配置文件中配置)提取提示词,目前是商品标题、品牌、类目、类型字段。不同的字段处理方法不同:
- 品牌、类目、类型字段是固定明确的,不需要分词
比如iphone 6s手机的品牌是苹果,类型是手机,这些直接作为提示词即可 - 标题字段需要分词
商品的标题为"Apple iPhone 6s (A1700) 64G 玫瑰金色 移动联通电信4G手机",真正可以作为提示词的有:“apple”、“iphone”、“6s”、“A1700”、“玫瑰金”、“4G手机”、“手机”、“iphone 6s”。目前任何一种中文分词方法分词结果都不能100%准确,经过比较,我们选择了ansj分词法作为我们的标题分词器。
通过扫描用户所有的商品,提取出关键词,经过计算处理后存放到搜索平台ES Suggest索引中。目前有两种方法触发提示词自动提取任务,一种是后台定时任务触发,一种是通过RESTFul接口由应用直接触发。
3.4. 提示词手工插入
将提示词结构中添加来源字段,目前分为自动提取和手工插入,手工插入的提示词默认权重较高,排序时会在前面。
提供提示词增删改查Restful接口,并且初始化提示词自动提取任务前只删除自动提取的提示词。
3.5. 索引与前缀查询(Trie树)
字符串前缀查询一般用Trie树实现,假设输入的提示词长度为len(q),则Trie树查询的复杂度为O(len(q)),Trie树的查询效率是要比Hash树高。我们可以给每个用户建一颗Trie树。介绍Trie树比较好的文章: 从Trie树(字典树)谈到后缀树。
为了速度可以考虑将提示词全部缓存到内存中,这样查询的速度是最快的。一般1w个商品自动提取的提示词也为1w,每个提示词的数据结构大小为100B,那么单个用户的所有的提示词大小为100000*100B=1MB,1000个有1w商品用户占用的内存大小为1GB,内存消耗还是可以承受的。
考虑使用Elasticsearch的Context Suggester模块实现,ES Context Suggest模块将所有提示词都加载到内存中,然后使用Trie树进行查找,查询时间10ms以内。
3.6. 提示词排序
排序的三个原则:
- 提示词包含的商品数量越多,提示词的顺序越靠前
- 被用户搜索的次数越多,提示词的顺序越靠前
- 手工添加的提示词(可能是推广)顺序靠前
我们设计通过weight(权重)字段进行排序,weight越高顺序越靠前,权重的计算公式:
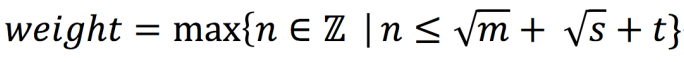
m表示提示词包含的文档数,s表示提示词被搜索次数,t表示提示词类型权重
每次更新提示词时都会重新计算权重,通过上面的公式计算得到的weight即满足排序的三个原则。
3.7. 从用户输入的关键词提取搜索建议
一个强大的系统应该具有自学习能力,用户输入的关键词也是一种宝贵的资源。比如很多用户搜索"iPhone 6s"、"iPhone 6s 玫瑰金",那么这些热词也可以作为提示词。目前我们的系统具有这样的能力,但是热门词不一定是合法词,系统不具备识别非法词的能力,所以系统的自学习功能不会上线。前不久微软的智能机器人就学习了很多脏话。